High Performance Queries: GPU vs. PLINQ vs. LINQ
Introduction
We hear increasingly about the power of graphics processing units for non-graphics purposes. NVIDIA's CUDA brought super computing ability within the reaches of the masses. Whereas a top of the range Intel i7 may give 80GFlops (80 billion floating point operations per second), a relatively cheap graphics card can reach 1TFlop (1 trillion operations). However, we find out quite quickly that the applications that can make use of the GPU are often rather isoteric - simulations of weather, cell reproduction, video and image rendering, financial predictions, physics, etc. Most programmers when concerned about performance at all are more likely to be involved in much more mundane work such as trawling through databases, parsing and generating XML, and matching records. Can a GPU be of use for such tasks?
Background
The introduction of LINQ (Language Integrated Query) to .NET simplified common tasks relating to searching of XML, databases, and objects. A typical application may involve a list of records, say website visits. The list contains millions of records detailing the visitor's IP address, browser type, date and time of visit, length of time on site, pages visited, etc. We may need to run a query to return visits on a certain day from certain countries. LINQ allows us to write a simple query that is applicable to a variety of sources - the list can be in XML, database, or object for example. The speed we get the results at is dependent on a number of factors especially when dealing with databases and XML files. If we restrict ourselves on objects, i.e., we already have the source data in memory in the form of a list, then we can more accurately measure performance differences between techniques.
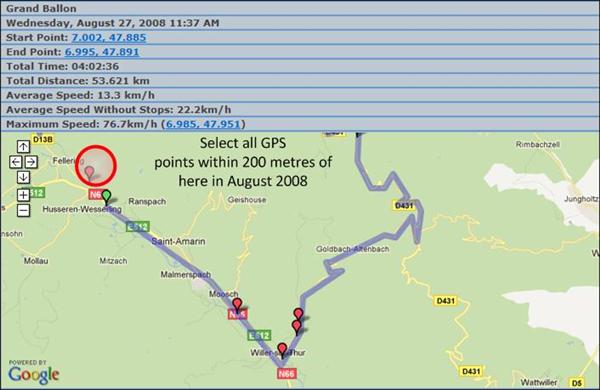
Doing simple comparisons such as on dates and short strings are handled relatively well by LINQ. PLINQ - which is a parallel extension of LINQ - can accelerate matters considerably and it can be trivial to use. We'll look at this, too. However, queries can be severely affected if a more complex query is required. In this article, we will consider a GPS track point database. This is a list of all the routes taken by a GPS recorder. This kind of functionality is commonly used in company trucks and cars to monitor where vehicles have been - this is increasingly required by tax authorities to prove private and work related mileage. In our example, we want to query our database of GPS points to return all points within a certain radius of a number of targets between a given start and end date. Doing this the brute force way of calculating the distance between two points on the earth's surface represents a tough challenge, and should prove to be a good example of the pros and cons of performing this with LINQ, PLINQ, and on a GPU.
Prerequisites
We will be using CUDAfy.NET for programming the GPU. The CUDAfy library is included in the downloads, however you will need to download and install CUDA 4.0 from NVIDIA if you wish to change the source code and recompile. In all cases, you will need a CUDA enabled NVIDIA GPU. Please see my previous articles for more information on getting up and running.
See this article on base64 encoding on a GPU, or this one as a basic introduction to CUDAfy and CUDA.
Using the code
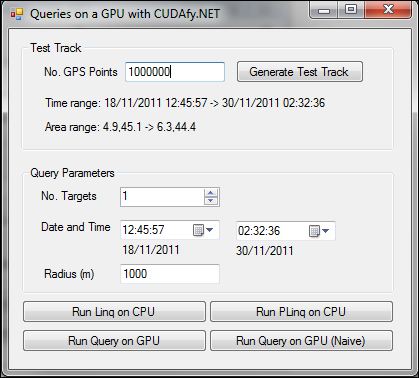
This application generates a random GPS route for a user defined number of points and then allows the user to input search criteria including:
- Number of targets.
- Date and time range.
- Radius from targets in meters.
- The same query can then be executed using LINQ, PLINQ, and GPU.
The basis of the code is the GPS track point and GPS track. These are defined as TrackPoint and Track. It would be convenient if the host and GPU code can be shared where possible:
Code which runs on the GPU is called device code, and it needs to be flagged so when CUDAfy converts to CUDA C code, it picks it up. To do this, add the Cudafy attribute.
[Cudafy]
[StructLayout(LayoutKind.Sequential)]
public struct TrackPoint
{
public TrackPoint(double lon, double lat, long timeStamp)
{
Longitude = lon;
Latitude = lat;
TimeStamp = timeStamp;
}
...
}
When Cudafying a struct, all members will be translated by default. To ignore a member, use the CudafyIgnore attribute. In this example, we have a property Time. This is a DateTime type. Properties and DateTime are not supported on the GPU so we need to flag it to be ignored.
[CudafyIgnore]
public DateTime Time
{
get { return new DateTime(TimeStamp); }
set { TimeStamp = value.Ticks; }
}
The method that will do the work in testing whether a GPS point is within radius meters of a target point is defined as:
public double DistanceTo(TrackPoint B)
{
double dDistance = Single.MinValue;
double dLat1InRad = Latitude * CONSTS.PI2;
double dLong1InRad = Longitude * CONSTS.PI2;
double dLat2InRad = B.Latitude * CONSTS.PI2;
double dLong2InRad = B.Longitude * CONSTS.PI2;
double dLongitude = dLong2InRad - dLong1InRad;
double dLatitude = dLat2InRad - dLat1InRad;
// Intermediate result a.
double a = Math.Pow(Math.Sin(dLatitude / 2.0), 2.0) +
Math.Cos(dLat1InRad) * Math.Cos(dLat2InRad) *
Math.Pow(Math.Sin(dLongitude / 2.0), 2.0);
// Intermediate result c (great circle distance in Radians).
double c = 2.0 * Math.Atan2(Math.Sqrt(a), Math.Sqrt(1.0 - a));
// Distance
dDistance = CONSTS.EARTHRADIUS * c;
return dDistance * 1000;
}
The shortest distance between any two points on the surface of the earth is given by the great circle distance. If you look at in-flight magazines, you'll see standard 2D maps that show you that your flight from Europe to California does so via Greenland. This goes much further north than either the departure or arrival point, and it is not done so in order to take the scenic route, but because it's the great circle. Calculating the distance requires a fair bit of double floating point math processing.
The other methods are included for completeness and do not run on the GPU within the context of this example, but please feel free to try them out yourself.
The code for running the query on the CPU is shown below. We pass an array of targets as well as the other query parameters. Then using the Where method of the LINQ extensions to the _track array, we return all points where the GetNearestTargetIndex method returns less than 255. If the value is 255, then the point was not within the radius of any of the targets, else the index of the target nearest to the point is returned. The standard LINQ will execute on a one processor core. To make use of more cores, simply insert AsParallel before the Where method.
private IEnumerable<TrackPoint> GetPoints(TrackPoint[] targets,
double radius, DateTime startTime, DateTime endTime, bool parallel)
{
long targetStartTime = startTime.Ticks;
long targetEndTime = endTime.Ticks;
// Running the query in parallel is as easy as adding AsParallel().
// We're not concerned with the ordering, so it's ideal.
if(parallel)
return _track.AsParallel().Where(tp => GetNearestTargetIndex(tp,
targets, radius, targetStartTime, targetEndTime) < 255);
else
return _track.Where(tp => GetNearestTargetIndex(tp, targets,
radius, targetStartTime, targetEndTime) < 255);
}
private byte GetNearestTargetIndex(TrackPoint tp, TrackPoint[] targets,
double radius, long targetStartTime, long targetEndTime)
{
double minDist = Double.MaxValue;
byte index = 255;
// If we're not within the time range then no need to look further.
if (tp.TimeStamp >= targetStartTime && tp.TimeStamp <= targetEndTime)
{
int noTargets = targets.Length;
// Go through the targets and get the index of the closest one.
for (int i = 0; i < noTargets; i++)
{
TrackPoint target = targets[i];
double d = tp.DistanceTo(target);
if (d <= radius && d < minDist)
{
minDist = d;
index = (byte)i;
}
}
}
return index;
}
Let's now look at the code that will communicate with the GPU. This is implemented in the Track class. The constructor takes care of Cudafying. This is the process of generating CUDA C code, compiling this, and then storing the output (PTX) into a module. This module can be serialized in order to save time in future runs or to run on an end user system without the NVIDIA CUDA SDK installed. Here we wish to Cudafy two types: Track and TrackPoint.
public Track()
{
// Does an already serialized valid cudafy module xml file exist. If so
// no need to re-generate it.
var mod = CudafyModule.TryDeserialize(csTRACK);
if (mod == null || !mod.TryVerifyChecksums())
{
mod = CudafyTranslator.Cudafy(typeof(Track), typeof(TrackPoint));
mod.Serialize(csTRACK);
}
// Get the default GPU device and load the module.
_gpu = CudafyHost.GetDevice();
_gpu.LoadModule(mod);
}
private const string csTRACK = "track";
The key to efficient use of a GPU for general purpose programming is to minimize the amount of data that needs to transfer between the host and the GPU device. Here we do this by first loading the track. We can then run multiple queries without having to reload the track. Since by default we're going to operate on 10,000,000 GPS points which represent 240,000,000 bytes (two System.Double and one System.Int64 fields per GPS point: longitude, latitude, and timestamp), this is important. The track is uploaded as an array of points. For clarity, variables that reside on the GPU are suffixed with _dev. As an optimization, if the already allocated memory on the GPU is greater than the new track to be uploaded, we do not free it and reallocate, but just use the required amount (_currentLength). The variable _indexes is an array of bytes equal to the length of the track. Per corresponding point, we will fill in either 255 if the point is not within the radius and date range of any of the targets, or the index of the target if it is within:
public void LoadTrack(TrackPoint[] trackPoints)
{
_currentLength = trackPoints.Length;
// If the current number of points on the GPU are less than the number of points
// we want to load then we resize the allocated memory on the GPU. We simply free
// the existing memory and allocate new memory. We need arrays on the GPU to hold
// the track points and the selected indexes. We make an array on the host to hold
// the returned indexes.
if (_trackPoints.Length < trackPoints.Length)
{
if (_trackPoints_dev != null)
{
_gpu.Free(_trackPoints_dev);
_gpu.Free(_indexes_dev);
}
_trackPoints_dev = _gpu.Allocate(trackPoints);
_indexes_dev = _gpu.Allocate<byte>(trackPoints.Length);
_indexes = new byte[trackPoints.Length];
}
_trackPoints = trackPoints;
// Copy the GPS points to the GPU.
_gpu.CopyToDevice(trackPoints, 0, _trackPoints_dev, 0, trackPoints.Length);
}
The method we will call from our application is SelectPoints. GPUs have multiple forms of memory. CPU only systems also do since the CPU has its own cache, however we never explicitly use this. However, on the GPU, use of different memory types is advisable as it can have a major impact on performance. The biggest and also slowest memory is global. That's where we've stored our track. Modern GPUs typically have at least 1GB of this memory. Another memory is constant memory. It can only be written to by the host. For the GPU, it is read-only and very fast. We will use it for storing our targets. Keep in mind that the amount of constant memory is very limited (think KBytes, not MBytes) and cannot be freed. Device functions are said to be launched. The Launch method of the GPU device takes the following parameters:
- Number of blocks of threads in the grid.
- Number of threads per block (maximum of 1024).
- Name of function to launch.
- Array of track points on device.
- The number of track points.
- Radius from targets in meters.
- Start time in ticks.
- End time in ticks.
- Array of bytes for result.
- The number of targets.
Launching essentially starts blocksPerGrid*ciTHREADSPERBLOCK threads in parallel. This number can be quite high but if the GPU function takes more than 0.5 seconds or so, then it is advisable to split the process into multiple calls. The NVIDIA driver does not like blocking the GPU for too long and the launch will time out beyond a point. Once done, we copy the _indexes_dev array back to the host and then search it for values less than 255, returning the corresponding TrackPoint. We could elect to do something with the index so we identify which target was closest. This can be done using the TrackPointResult struct which is included in the sources as an example.
public IEnumerable<TrackPoint> SelectPoints(TrackPoint[] targets,
double radius, DateTime startTime,
DateTime endTime, bool naive = false)
{
int blocksPerGrid;
// Validate the parameters and calculate how
// many blocks of threads we will need on the GPU.
// Each block of threads will execute ciTHREADSPERBLOCK threads.
Initialize(radius, startTime, endTime, out blocksPerGrid);
// Copy the targets to constant memory.
_gpu.CopyToConstantMemory(targets, 0, _targets, 0, targets.Length);
// Launch blocksPerGrid*ciTHREADSPERBLOCK threads in parallel.
// Each thread will test one GPS point against all targets.
_gpu.Launch(blocksPerGrid, ciTHREADSPERBLOCK, "SelectPointsKernel",
_trackPoints_dev, _currentLength, radius,
startTime.Ticks, endTime.Ticks, _indexes_dev, targets.Length);
// Copy the indexes array back from the GPU to the host
// and search for all points that have an index < 255.
// These correspond to GPS points lying within the search criteria.
_gpu.CopyFromDevice(_indexes_dev, 0, _indexes, 0, _currentLength);
for (int i = 0; i < _currentLength; i++)
{
byte index = _indexes[i];
if (index < 255)
yield return _trackPoints[i];
}
}
Each thread executes the following device code which performs a test on one point. GThread identifies the unique ID of the thread so the thread knows which point to access. For this example, we will make use of yet another form of GPU memory: shared. This memory is shared between all the threads within one block. When inefficient use of the global memory is made by, for example, reading small amounts of data in a non-sequential way, performance suffers. In such instances, it is better to use shared memory as an intermediate storage. Having said all that, the new Fermi architectures appear to do a very good job of handling this code, and the simpler implementation SelectPointsKernelNaive will run as fast as the one below with shared memory. Try it and see.
[Cudafy]
public static void SelectPointsKernel(GThread thread, TrackPoint[] track,
int noPoints, double radius, long startTime, long endTime,
byte[] indexes, int noTargets)
{
// Here we use another form of GPU memory called shared memory.
// This is shared between threads of a single block.
// The size of the shared memory must be constant
// and here we set it to the number of threads per block.
// This can be more efficient than the naive implementation below,
// however on the latest fermi architecture there is little
// or no difference.
byte[] cache = thread.AllocateShared<byte>("cache", ciTHREADSPERBLOCK);
// Get the unique index of the thread: size of the
// block * block index + thread index.
int tid = thread.blockDim.x * thread.blockIdx.x + thread.threadIdx.x;
// Check we are not beyond the end of the points.
if (tid < noPoints)
{
TrackPoint tp = track[tid];
double minDist = Double.MaxValue;
byte index = 255;
if (tp.TimeStamp >= startTime && tp.TimeStamp <= endTime)
{
for (int i = 0; i < noTargets; i++)
{
// get the target from constant memory
TrackPoint target = _targets[i];
// Calculate distance to target and if less
// than radius and current nearest target
// set minDist and index.
double d = tp.DistanceTo(target);
if (d <= radius && d < minDist)
{
minDist = d;
index = (byte)i;
}
}
}
// set the index.
cache[thread.threadIdx.x] = index;
// Synchronize all threads in block
thread.SyncThreads();
// Write the results into global memory array
indexes[tid] = (byte)cache[thread.threadIdx.x];
}
}
Benchmarks
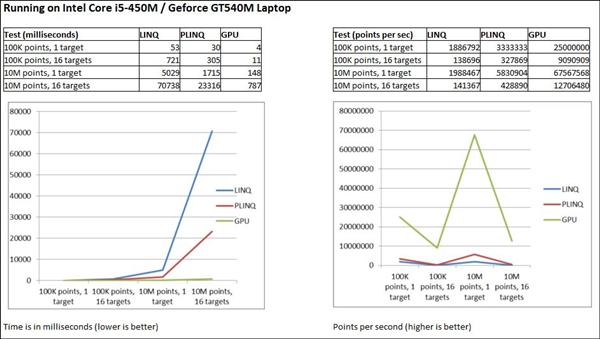
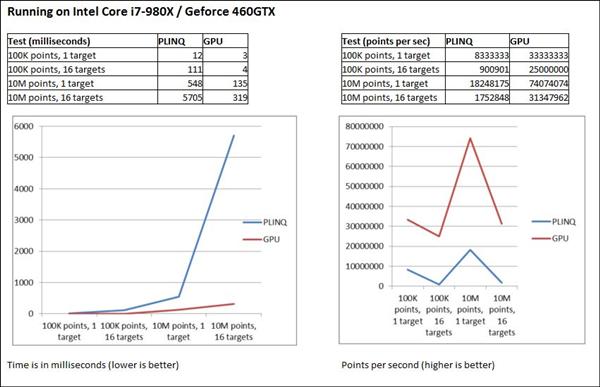
The results were rather impressive. We see that the use of PLINQ gives a very worthwhile benefit over LINQ but for very demanding applications, the GPU comes into its own with up to 30 times improvement in this example. Even if the track requires re-uploading to the GPU (cost of 150ms on the laptop), the advantage remains considerable. This is very significant and means that using a GPU in more normal line of business applications should be considered. The code here can be readily adapted for other purposes. When integrated into a (web) server application, the load could be drastically reduced providing worthwhile cost savings in terms of equipment and energy.
License
The Cudafy.NET SDK includes two large example projects featuring amongst others ray tracing, ripple effects, and fractals. It is available as a dual license software library. The LGPL version is suitable for the development of proprietary or Open Source applications if you can comply with the terms and conditions contained in GNU LGPL version 2.1. Visit the Cudafy website for more information.
History
First release.
 "
"